

تتدفَّق المعلومات في عصرنا المترابط بلا توقُّف، إذ أصبحت البيانات المحرِّك الخفي لكل قرار، من تطوير التطبيقات الجديدة، إلى صياغة السياسات العامة، وحتى التنبؤ بالأحداث الاقتصادية والاجتماعية.
فَتَحَت هذه القدرة الهائلة على جمع وتحليل البيانات آفاقًا غير مسبوقة للابتكار، وبنفس الوقت سلَّطت الضوء على تحدٍ بالغ الأهمية:
كيف يمكننا أن نحمي خصوصية الأفراد و أن نستفيد من قوة البيانات في نفس الأوان؟
إخفاء الهوية (Anonymization) هو أحد الأدوات التي ظهرت لمواجهة هذا التحدي، إذ تهدف هذه العملية إلى إزالة أو تعديل العناصر التي قد تكشف هوية الأشخاص داخل مجموعات البيانات، مع الحفاظ على القيمة التحليلية للمعلومات. تتنوَّع الأساليب بين حلول تقليدية مثل حذف المُعرِّفات المباشرة أو استبدالها، وتقنيات إحصائية مثل التمويه الكافيّ (k-anonymity)، وصولًا إلى منهجيات متقدِمة مثل الخصوصية التفاضلية التي تقدِّم ضمانات رياضية ضدّ إعادة التعريف.
لكن على الرغم من انتشار هذه التقنيات، أثبتت التجارب الواقعية أنّ الاعتماد على إخفاء الهوية وحده لا يكفي دائمًا. فقد أظهرت حالات شهيرة حول العالم أن البيانات المجهولة، يمكن أن يُعاد ربطها بسهولة بمصادر أخرى، وهذا قد يؤول إلى كشف الهويات والمعلومات الحساسة. يزداد هذا الخطر مع تضخُّم أحجام البيانات وتنوُّع مصادرها، إذ يمكن لأي خوارزمية أو محلِّل بيانات ماهر أن يجد نقاط التلاقي التي تكشف عن الصورة الكاملة.
اليوم، ومع اشتداد القوانين المتعلقة بحماية البيانات مثل اللائحة العامة لحماية البيانات (GDPR) في أوروبا، والضغوط المتزايدة من قبل المجتمع المدني والمستخدمين، أصبح من الضروري على المؤسسات والأفراد أن تبني استراتيجيات أكثر شمولًا ووعيًا لإخفاء الهوية. لا تقتصر هذه الاستراتيجيات على اختيار أداة تقنية، بل تمتد لتشمل وضع سياسات واضحة، وتدريب الفرق العاملة، وتقييم المخاطر باستمرار، مع مراعاة الموازنة بين الخصوصية وفائدة البيانات.
لماذا يُعَدّ إخفاء الهوية أمرًا مهمًّا في عصر البيانات؟
مع التحوُّل الرقمي الهائل في العقدين الأخيرين، أصبحت البيانات تُجمَّع وتُخزَّن بكميات غير مسبوقة، من معاملات التسوق عبر الإنترنت، وتطبيقات الصحة واللياقة، إلى سجلَّات الحكومات والبنوك. هذه البيانات ليست مجرد أرقام أو نصوص؛ بل انعكاس مباشر لحياة الأفراد، وعاداتهم، وتفضيلاتهم، وحتى حالتهم الصحية أو المالية.
في بيئة كهذه، قد يؤدي أي تسريب معلومات إلى أضرار وخيمة، من انتهاك الخصوصية والابتزاز، أو التمييز، أو حتى تهديد السلامة الجسدية. لا هذه المشكلة على الجهات الخبيثة فقط، فحتى المشاركات حسنة النية مثل نشر بيانات للبحث العلمي أو التحليل الإحصائي، قد تتحول إلى تهديد إذا لم تُعالج بصورة تضمن أنّ الهوية مخفية.
لا تقتصر أهمية إخفاء الهوية اليوم على جانبه التقني، فهو أصبح:
- درعًا وقائيًا ضد الهجمات السيبرانية: في حال تعرضت الأنظمة للاختراق، تقلِّ خطورة البيانات المُجهَّلة مقارنة بالبيانات الخام.
- متطلبًا قانونيًّا وتنظيميًا: تشترط قوانين مثل اللائحة العامة لحماية البيانات أو قانون حماية خصوصية المستهلك في كاليفورنيا على حماية بيانات الأفراد، وتفرض غرامات باهظة على المخالفين.
- أداة لبناء الثقة: الأفراد والمؤسسات أكثر استعدادًا للمشاركة والتعاون عند تيقُّنهم بأن احتمالية تعريف هوِّيتهم منخفضة.
- طريقة لمشاركة البيانات بأمان أكبر: تمكين الباحثين والمطورين من العمل على مجموعات بيانات حقيقية دون كشف هوية أصحابها.
في هذا العصر الذي أصبحت فيه البيانات "وقود" الابتكار، لا يعد إخفاء الهوية رفاهية أو خيارًا ثانويًا، بل عنصرًا أساسيًا في أي استراتيجية للأمن الرقمي وإدارة البيانات.
المفاهيم الأساسية لإخفاء الهوية
عند الحديث عن حماية البيانات الشخصية، من الضروري فهم المصطلحات والمفاهيم الأساسية المرتبطة بعملية إخفاء الهوية، لأنها تحدد مدى قوة الحماية التي يمكن أن توفرها أي تقنية. الجدول أدناه يبين أهم هذه المصطلحات:
| إخفاء الهوية (Anonymization) والتسمية المستعارة (Pseudonymization) | إخفاء الهوية هو تقنية لمعالجة البيانات تُزيل أو تُعدّل معلومات تحديد الهوية الشخصية، فتسفر هذه التقنية عن بيانات مخفية الهوية لا يمكن أن تُنسَب لأي فرد من الأفراد، حتى من قِبل الجهة التي تملكها. أمّا التسمية المستعارة فهي استبدال المُعرِّفات المباشرة (مثل الاسم أو رقم الهوية) برموز أو أكواد، مع الاحتفاظ بمفتاح الربط في مكان آمن، ممّا يعني أنّ استرجاع البيانات الأصلية ممكن إذا توفر هذا المفتاح. وفق اللائحة العامة لحماية البيانات (GDPR)، البيانات المُجهَّلة بالكامل تخرج من نطاق القانون، بينما البيانات المستعارة تبقى محمية لأنها قابلة لإعادة الربط. |
| المُعرِّفات المباشرة (Direct Identifiers) | هي عناصر بيانات تكشف هوية الشخص مباشرة إذا ظهرت، مثل الاسم الكامل، أو البريد الإلكتروني الشخصي، أو رقم الهوية، أو العنوان الكامل، فوجود هذه المُعرِّفات يُقلِّل من فعالية عملية إخفاء الهوية إذا لم تُزال أو تُعدَّل. |
| المُعرِّفات الشبهية (Quasi-identifiers) | هي بيانات لا تكشف الهوية وحدها، لكنها قد تسمح بالتعرُّف على الشخص إذا جُمِعت مع بيانات أخرى. من أمثلتها تاريخ الميلاد، والرمز البريدي، والجنس، والمهنة. وقد أثبتت بعض الدراسات أن الجمع بين العمر والجنس والرمز البريدي يمكن أن يُحدِّد هوية نسبة كبيرة من الأفراد. |
| البيانات الحساسة (Sensitive Attributes) | هي المعلومات التي ترتبط ارتباطًا وثيقًا بحياة الشخص الخاصة، مثل الحالة الصحية، أو الديانة، أو الميول السياسية، أو الوضع المالي. حتى في حالة إزالة الهوية، يظل الكشف عن هذه المعلومات خطيرًا إذا كانت مرتبطة بمجموعة صغيرة أو إذا كان استنتاجها ممكنًا. |
| إعادة التعريف (Re-identification) | يُقصَد بها استخدام مصادر بيانات أخرى —سواء كانت عامة أو خاصة— لربط مجموعة بيانات "مجهولة" بهوية فرد معين. أثبتت حالات شهيرة، مثل إعادة تعريف بيانات طبية في ماساتشوستس أو بيانات تقييمات «نتفليكس»، أنّ تقنيات الإخفاء التقليدية قد لا تصمد أمام هجمات الربط المتطورة. |
كلما زاد مستوى إخفاء الهوية من خلال حذف أو تعميم التفاصيل الدقيقة، انخفضت فائدة البيانات في التحليل أو البحث. التحدي أمام المؤسسات هو إيجاد التوازن بين توفير حماية قوية للخصوصية، والحفاظ على القيمة التحليلية والعملية للبيانات.
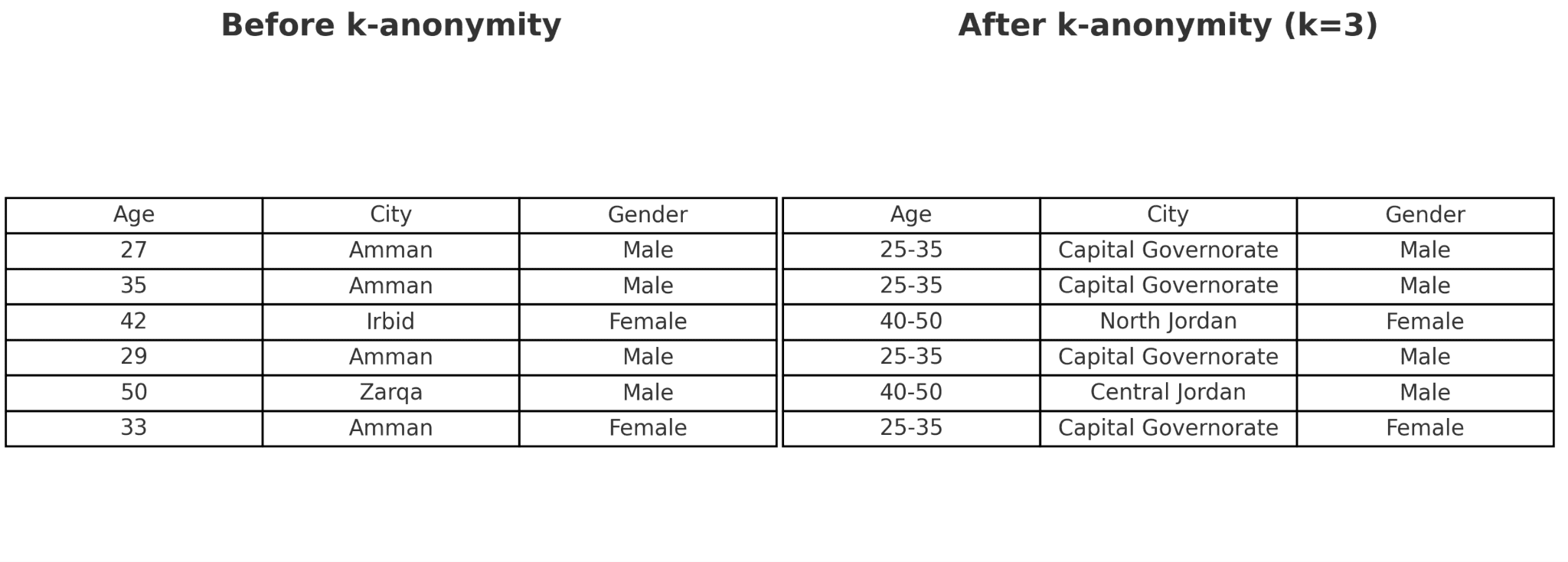
التقنيات التقليدية لإخفاء الهوية ومشكلاتها
كلما زاد عدد السمات في البيانات، يصبح الحفاظ على التمويه الكافيّ دون فقدان فائدة البيانات أصعب بمراحل.
هجمات قد تكسر تقنيّات الحماية
على الرغم من أن تقنيات مثل التشفير بالهاش والتمويه الكافيّ توفر طبقة مهمة من الحماية، إلّا أنها ليست منيعة بالكامل أمام محاولات إعادة التعريف أو استرجاع البيانات الأصلية، التطور السريع في أدوات التحليل وقدرات المعالجة الحاسوبية مكَّن أفرادًا، في كثير من الحالات، من كسر هذه الأساليب أو الالتفاف حولها.
يمكن أن تُقسَّم الهجمات إلى فئتين رئيسيتين: هجمات على الهاش وهجمات على التمويه الكافيّ.
أولًا: هجمات على التشفير بالهاش (Hashing Attacks)
- هجمات جداول القوس القزح (Rainbow Table Attacks)
تعتمد على قواعد بيانات ضخمة تحتوي على أزواج من القيم النصية الأصلية وقيم الهاش المقابلة لها. إذا حصل المهاجم على قيمة الهاش، يمكنه أن يبحث عنها في هذه الجداول لاستنتاج النص الأصلي. تنجح هذه الهجمات غالبًا مع البيانات القصيرة أو الشائعة، مثل كلمات المرور الضعيفة أو أرقام الهواتف، ويمكن التصدي لها بإضافة قيمة عشوائية (ملح) فريدة لكل سجل. - هجمات القوة الغاشمة (Brute-force Attacks)
تقوم على تجربة جميع الاحتمالات الممكنة حتى يتم العثور على قيمة تنتج نفس الهاش. يعتمد نجاح هذه الهجمات على قوة المعالجة الحاسوبية التي يمتلكها المهاجم، ومدى تعقيد وطول البيانات الأصلية، فزيادة طول وتعقيد القيم واستخدام خوارزميات قوية يقلّل من فائدة هذه الهجمات. - هجمات التصادم (Hash Collision Attacks)
تحاول إيجاد قيمتين مختلفتين تنتجان نفس البصمة الرقمية. هذا النوع من الهجمات ممكن عمليًا ضد خوارزميات قديمة مثل MD5 وSHA-1، ما يجعل استبدالها بخوارزميات أكثر أمانًا مثل SHA-256 أو SHA-3 ضرورة أساسية. - غياب "الملح" (Lack of Salting)
إذا وُلِّد الهاش دون إضافة قيمة عشوائية (ملح)، تصبح القيم المتكررة عبر مجموعات بيانات مختلفة معرَّضة لنفس الهجمات. إضافة ملح عشوائي وفريد لكل سجل يزيد من صعوبة استخدام القواميس أو جداول القوس القزح بفاعلية.
ثانيًا: هجمات على التمويه الكافيّ
كلما زاد عدد الحقول أو السمات في البيانات، أصبحت أكثر تفرّدًا، مما يُصعِّب من تحقيق التمويه الكافيّ دون فقدان كبير في التفاصيل. قد تكون النتيجة إما بيانات محمية قليلة الفائدة، أو بيانات مفيدة قليلة الحماية.
التقنيات الحديثة والبدائل المتقدمة
أثبتت التجارب أن الأساليب التقليدية لإخفاء الهوية لم تعد كافية بمفردها لمواجهة مخاطر إعادة التعريف.
لهذا ظهرت تقنيات حديثة تقدم مستويات أعلى من الحماية، وغالبًا ما تعتمد على أسس رياضية أو تشفيرية قوية، وفي بعض الأحيان تُدمَج مع أساليب تقليدية لتحقيق أفضل النتائج.
١. الخصوصية التفاضلية (Differential Privacy)
الخصوصية التفاضلية هي إطار رياضي يهدف إلى حماية هوية الأفراد عن طريق إضافة ضوضاء مدروسة إلى البيانات أو نتائج الاستعلامات.
الفكرة الأساسية هي ضمان أن وجود أو غياب أي فرد في مجموعة البيانات لن يؤثر بشكل ملحوظ على النتيجة النهائية.
كيف تعمل؟
عند استخراج إحصائية من البيانات، تُضاف قيم عشوائية محسوبة بدقة إلى النتيجة، مما يجعل من المستحيل تقريبًا التأكد من مساهمة فرد محدد.
الفوائد:
- ضمانات رياضية قوية ضد إعادة التعريف.
- تُستخدم حاليًا في أنظمة شركات كبرى مثل «آبل، وغوغل، وويكيبيديا».
القيود:
- إضافة الكثير من الضوضاء قد يقلِّل من دقة النتائج.
- اختيار المعامل الرياضي ε يتطلب توازنًا دقيقًا بين الخصوصية وفائدة البيانات.
٢. البيانات الاصطناعية (Synthetic Data)
البيانات الاصطناعية هي بيانات تُنشَأ بواسطة نماذج إحصائية أو خوارزميات تعلم آلي لتقليد خصائص البيانات الحقيقية دون أن تُمثِّل أي فرد حقيقي.
كيف تعمل؟
تُحلَّل البيانات الأصلية لبناء نموذج يحاكي توزيعها وأنماطها، ثم تولَّد بيانات جديدة تحمل نفس الخصائص.
الفوائد:
- يمكن مشاركتها بحرّية لأنها لا تحتوي على بيانات شخصية مباشرة.
- تحتفظ بقدر كبير من القيمة التحليلية إذا وُلِّدَت بعناية.
القيود:
- إذا كانت عملية التوليد ضعيفة، قد تُسرِّب أنماطًا أو علاقات من البيانات الحقيقية.
- قد لا تُمثِّل جميع التعقيدات الموجودة في البيانات الأصلية.
٣. التشفير المتقدم
أ. الحوسبة متعدِّدة الأطراف (Multi-Party Computation – MPC)
تُمكِّن جهات عدة من التعاون في إجراء عمليات حسابية على بياناتهم المشتركة دون أن تُكشَف هذه البيانات لبعضهم البعض.
تُستخدم هذه التقنية في البيئات التي تتطلب التعاون مع الحفاظ على سرية البيانات.
ب. التشفير المتماثل أثناء التنفيذ (Fully Homomorphic Encryption – FHE)
يسمح بمعالجة البيانات وهي مشفَّرة بالكامل، بحيث يمكن تنفيذ العمليات الحسابية دون الحاجة لفك التشفير، ممّا يمنع أي جهة من الاطِّلاع على المحتوى الأصلي.
ج. البيئات الموثوقة (Trusted Execution Environments – TEE)
هي مناطق آمنة داخل المعالج يمكنها أن تُشغِّل الشيفرة وأن تُعالِج البيانات بمعزل عن النظام الرئيسي، ممّا يقلل من مخاطر الاختراق أو التلاعب.
٤. التقنيات الهجينة (Hybrid Approaches)
في كثير من الأحيان، نحصل على أفضل النتائج عند الجمع بين أكثر من تقنية. على سبيل المثال:
- تطبيق التعميم على البيانات، ثم إضافة خصوصية تفاضلية للنتائج.
- توليد بيانات اصطناعية من مجموعة بيانات تم إخفاء هويتها مسبقًا.
يساعد هذا الدمج على تحقيق توازن بين الخصوصية العالية والحفاظ على جودة البيانات للاستخدامات العملية.
٥. سياسات التحكم في الوصول (Access Control Policies)
حتى أقوى تقنيات إخفاء الهوية يمكن أن تفشل إذا كانت البيانات متاحة لكل من يريد الوصول إليها.
لهذا، تُعتبَر سياسات التحكم في الوصول جزءًا أساسيًا من أي استراتيجية لحماية البيانات، وتشمل:
- تحديد من يمكنه الوصول إلى أي جزء من البيانات.
- تطبيق مبدأ "أقل قدر ممكن من الصلاحيات" بحيث يحصل كل مستخدم على الحد الأدنى من البيانات التي يحتاجها فقط.
- مراقبة عمليات الوصول وتسجيلها لاكتشاف أي نشاط غير طبيعي.
بناء بيئة حماية متكاملة للبيانات
يتطلب تحقيق حماية فعّالة للبيانات الجمع بين تقنيات عديدة في إطار واحد متكامل، بحيث تعمل الطرق التقليدية جنبًا إلى جنب مع الأدوات الحديثة لتوفير مستويات متعدِّدة من الأمان.
تلعب سياسات التحكم في الوصول دورًا أساسيًا هنا، فهي تحدد من يملك صلاحية الاطِّلاع على البيانات أو تعديلها، وتوفر طبقة دفاعية إضافية ضدّ المخاطر الداخلية والخارجية.
كما أن الوعي والتدريب المستمر لجميع المعنيين بإدارة البيانات من مطورين وباحثين وحتى الموظفين في مختلف الأقسام يضمن أن كل الأطراف مدرِكة للمخاطر المحتملة وكيفية التصرف عند التعامل مع المعلومات الحسّاسة.
يشكل هذا الدمج بين التقنية والسياسة والوعي أساسًا متينًا لأي منظومة تسعى للحفاظ على الخصوصية وتقليل فرص الاختراق أو إساءة الاستخدام.
